因为新肺炎疫情,从年前29就开始在家隔离到现在,希望疫情早日结束。虽然在家,工作还是要继续做滴。这两天在家解决了一个隐藏比较深的bug,查找的过程也比较曲折,所以印象比较深刻。我一直非常的小心使用锁,了解死锁导致的各种可能性,这次的经历让我未来会更加小心,下面来回顾一下死锁发生的过程与解决的过程吧。
问题出现与分析
刚开始出现这个问题,是运维同学反馈说服务失败率超过1%。然后就去看服务是否正常运行,查看了其中某几台服务器上的业务日志和服务系统日志,发现都挺正常,没有error或者panic信息。就怀疑是不是误报,感觉也不大可能呀,然后去zabbix查看服务器的CPU utilization和memory usage情况;发现CPU utilization都听正常,但其中一台机器memory usage飙升;刚才看服务日志都挺正常,感觉是不是某个地方抽风导致。随即派上重启大法,然后一切恢复正常。
不过雷在这边,不排除掉终究是个隐患,但一下子也没有头绪。抛开杂念后就开始梳理,情况比较明显,是内存使用过高导致服务异常,但内存为什么突然飙升呢?当时goroutine数量又是什么情况呢?会不会是goroutine泄漏导致内存飙升?根据以往经验,没有error异常日志,有可能是这个样子滴。想到就去干, 加监控,收集日志 , 于是在代码中加了下面代码
ticker := time.NewTicker(30 * time.Second)
memStatus := runtime.MemStats{}
var (
goroutineNum int
headSys int
heapInUse int
instNo string
)
instNo = os.Getenv("INST_NO")
if instNo == "" {
instNo = "1"
}
go func() {
for {
<-ticker.C
goroutineNum = runtime.NumGoroutine()
runtime.ReadMemStats(&memStatus)
headSys = int(memStatus.HeapSys) / 1048576 //字节转换成Mb
heapInUse = int(memStatus.HeapInuse) / 1048576
//监控上报
//goroutine数量
GoroutineHistogram.With(prometheus.Labels{"inst_no": instNo}).Set(float64(goroutineNum))
//分配堆占用情况
HeapSysHistogram.With(prometheus.Labels{"inst_no": instNo}).Set(float64(headSys))
//当前堆使用情况
HeapInUseHistogram.With(prometheus.Labels{"inst_no": instNo}).Set(float64(heapInUse))
if item.MaxGoroutineNum > 0 && goroutineNum > item.MaxGoroutineNum {
//goroutine数量超过最大数量(默认 1000),则打印栈信息
dumpStacks()
}
}
}()
...
func dumpStacks() {
buf := make([]byte, 1024)
for {
n := runtime.Stack(buf, true)
if n < len(buf) {
buf = buf[:n]
break
}
buf = make([]byte, 2*len(buf))
}
sdk.INFO.Printf("=== BEGIN goroutine stack dump ===\n")
sdk.INFO.Printf("%s", buf)
sdk.INFO.Printf("=== END goroutine stack dump ===\n")
}
然后发布上线,静候问题复线
问题定位
功夫不负有心人,上线后某个时间突然收到告警通知。

设置告警阈值是 1G,而告警内容中当前堆分配内存已超过 20G
立马先把对应机器上的服务重启,然后再去分析原因 后面看了下 promethues监控,不出所料,此时goroutine数量也从正常的60多飙升到快5W了,如果不是重启的话,估计还会继续涨,最终导致oom
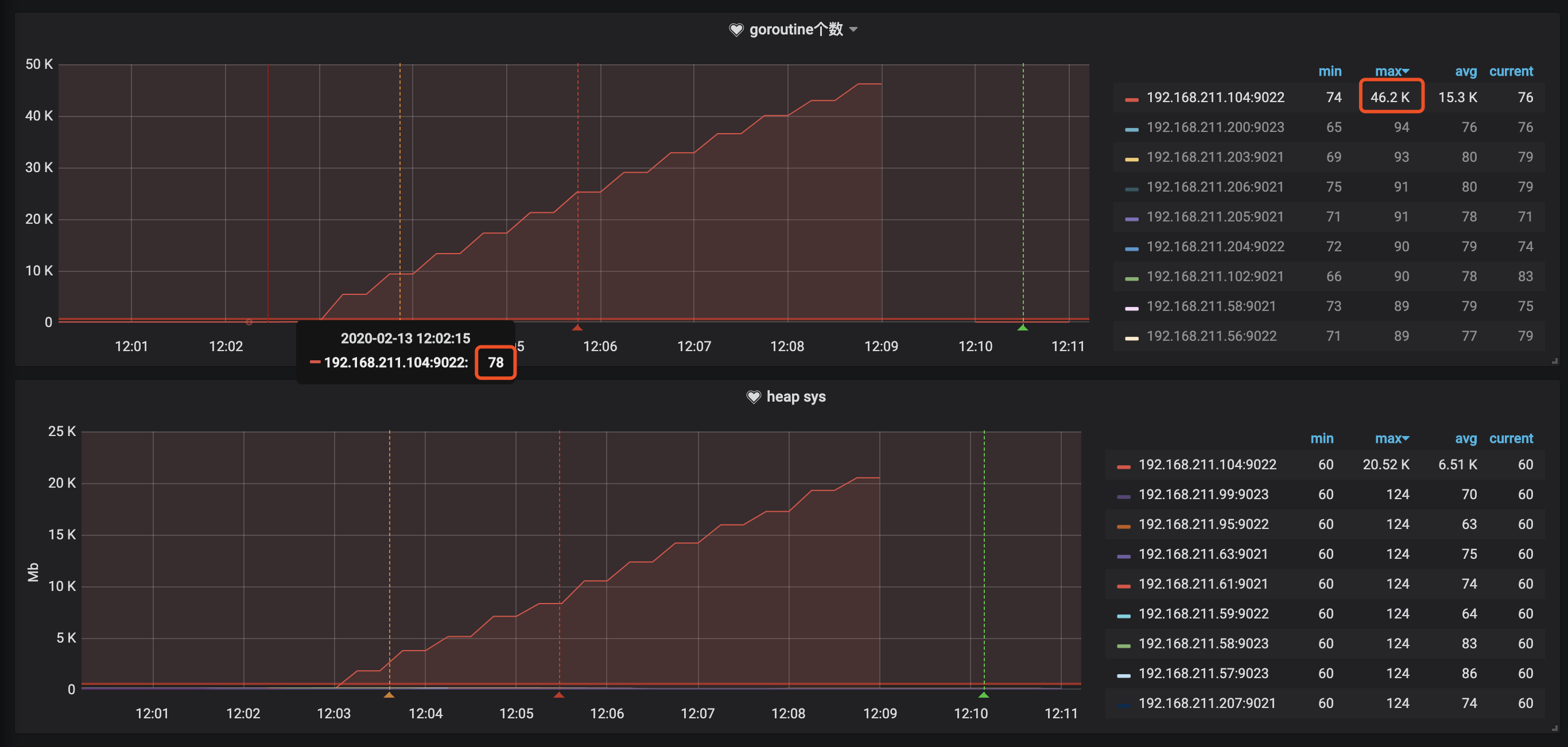
所以基本就确定goroutine数量飙升导致内存消耗过多,然后去看堆栈信息 统计了下,此时goroutine总量为 47905,而其中某个goroutine数量却有 47841个

再接着看这个goroutine是干啥的

原来这个goroutine在申请互斥锁中的写锁时被阻塞了,所以问题就是为啥申请写锁时被阻塞了呢?
业务介绍
这块业务主要和缓存有关,有个hashSet : map[string]struct{}{}存放key信息,另外有个cache: map[string]myData 存放相关业务信息 (1). 有个goroutine定时每1分钟,从hashSet中读取到所有key;遍历key从存储中读取最新数据 然后更新这个cache map中 (2). 主进程中,会实时从cache map中根据key读取相关数据;如果读取不到,则把key添加到hashSet中,定时goroutine会读取这个key的信息,然后更新到 cache map中
其中(1) 相关代码
遍历key
// Values returns all items in the set.
func (set *HashSet) Values() []string {
set.mu.RLock()
defer set.mu.RUnlock()
values := make([]string, set.Size())
count := 0
for item := range set.items {
values[count] = item
count++
}
return values
}
...
// Size returns number of elements within the set.
func (set *HashSet) Size() int {
set.mu.RLock()
defer set.mu.RUnlock()
return len(set.items)
}
(2) 相关代码
// Add one item into the set.
func (set *HashSet) AddOne(item string) {
set.mu.Lock()
set.items[item] = itemExists
set.mu.Unlock()
}
而从刚开的堆栈信息,可以看到,在执行 AddOne() 函数时,申请写锁被阻塞死锁了 咋一看,代码也没问题呀!读锁释放后,写锁就会申请成功了,怎么会发生死锁呢
然后继续绞尽脑汁深入分析,果然有些问题,大概原因是这样的
- 定时gorontine遍历更新数据时,执行 Values(),此时会申请读锁 a ,这个锁会在for循环执行完毕,return前释放
- Values()中会调用 set.Size()函数,而Size()函数中也用到了读锁 b,这个锁很快就释放了
- 主进程调用 AddOne() 时会用到 写锁 a
而当开始执行1时,会申请读锁a;如果在进入for循环前,主进程调用AddOne(),就会去申请写锁a;此时读取a还未释放,所以写锁a申请就处于排队阻塞状态;而Value()会继续往下执行,进入Size()函数;Size函数又去申请读锁b,这个时候写锁a还在排队,所以读锁b申请失败,等待写锁a处理完毕,进而导致for循环执行不下去;而读锁a要等到for循环执行完毕才能释放
所以就进入死锁,写锁a等待读锁a释放;读锁b等待写锁a完成;读锁a只能在for循环执行完毕后才能释放,而for循环又被读锁b的申请阻塞 执行不下去
原因找到后,就好解决了
解决方案
针对上面情况,解决起来改动比较小,把上面三环中的一环去掉(把读锁b去掉)就可以了
// Values returns all items in the set.
func (set *HashSet) Values() []string {
set.mu.RLock()
values := make([]string, len(set.Items())
count := 0
for item := range set.items {
values[count] = item
count++
}
set.mu.RUnlock()
return values
}
总结
- 碰到棘手问题时,要想办法定位到问题,总有解决方案的
- 不要再大一点的函数里 写 大量的 锁和defer 解锁