什么是curl
我们在平时开发过程中,会经常使用curl来抓取数据,但是curl到底是什么呢?我们为什么要使用curl呢?
curl是利用URL语法在命令行方式下工作的开源文件传输工具,使用URL的语法模拟浏览器来传输数据。
因为它是模拟浏览器,因此它同样支持多种协议:FTP, FTPS, HTTP, HTTPS, GOPHER, TELNET, DICT, FILE 以及 LDAP等协议都可以很好的支持,包括一些:HTTPS认证,HTTP POST方法,HTTP PUT方法,FTP上传,keyberos认证,HTTP上传,代理服务器,cookies,用户名/密码认证,下载文件断点续传,上传文件断点续传,http代理服务器管道,甚至它还支持IPv6,scoket5代理服务器,通过http代理服务器上传文件到FTP服务器等等。
这就是我们为什么要使用curl的原因!
【使用curl完成简单的请求主要分为以下四步:】
- 初始化,创建一个新cURL资源
- 设置URL和相应的选项
- 抓取URL并把它传递给浏览器
- 关闭cURL资源,并且释放系统资源
我们来采集一个页面,通常情况下,我们会使用file_get_contents()函数来获取: 但是我们会发现,我们没有办法有效地进行错误处理,更重要的是我们没有办法完成一些高难度的任务:处理cookies,验证,表单提交,文件上传等等。
什么是curl_multi
大家都知道php没有多线程,这也是弱于java等高级语言的表现之一。
但有时候我们还是需要php同时做一些操作,这时候我们可以借助服务器的多程线来实现。
自然就会想起 curl_multi_* 系列函数,这些函数说明并不详细,例子也很少。
一般来说,想到要用这些函数时,目的显然应该是要同时请求多个url,而不是一个一个依次请求。
步骤总结如下:
- 调用curl_multi_init
- 循环调用curl_multi_add_handle(这一步需要注意的是,curl_multi_add_handle的第二个参数是由curl_init而来的子handle)
- 持续调用curl_multi_exec
- 根据需要循环调用curl_multi_getcontent获取结果
- 调用curl_multi_remove_handle,并为每个字handle调用curl_close
- 调用curl_multi_close
curl VS curl_multi
curl_init()处理事物是单线程模式,如果需要对事务处理走多线程模式,那么php里提供了一个函数curl_multi_init()给我们,这就是多线程模式处理事务的函数。
那么通过for循环调用curl 和 调用curl_multi多现成,两种方式的效率如何呢?
我用抓取网站图片作为例子:先抓取一个网站的html,然后通过正则匹配出html中的所有图片,通过两种方式把所有图片都抓取下来,代码如下:
代码
curl:
<?php
error_reporting(E_ALL ^ E_NOTICE);
/**
* 远程图片并行下载
*
* 确保服务器配置有curl
*
* @param string $url
* @param string $save_path
* @return void
*/
function graber_remote_image($url, $save_path="./") {
set_time_limit(0);
ignore_user_abort(true);
if(!in_array('curl', get_loaded_extensions())){
die("curl not support !");
}
$ch = curl_init();
curl_setopt_array($ch, array(
CURLOPT_URL => $url,
CURLOPT_CONNECTTIMEOUT => 30,
CURLOPT_REFERER => !empty($_SERVER["HTTP_REFERER"]) ? $_SERVER["HTTP_REFERER"] : "",
CURLOPT_RETURNTRANSFER => 1,
CURLOPT_FOLLOWLOCATION => 1,
CURLOPT_USERAGENT => $_SERVER['HTTP_USER_AGENT']
));
$message = curl_exec($ch);
if(preg_match_all("/(http:\/\/|www\.)[^ \"']+/i", $message, $matches)){
$images_links = array();
foreach ($matches[0] as $item) {
$suffix = pathinfo($item, PATHINFO_EXTENSION);
if(in_array(strtolower($suffix), array('gif', 'png', 'jpg'))) {
array_push($images_links, $item);
//在这里进行简单修改可以选择性下载不同格式文件
}
}
}
if(empty($images_links)) {
die('get nothing image inforation.');
}
$images_links = array_unique($images_links);
@mkdir($save_path, 0777, true);
// Download images
$mh = curl_multi_init();
$handle = array();
foreach($images_links as $k=>$item_url){
$filename = pathinfo($item_url, PATHINFO_BASENAME);
$curl = curl_copy_handle($ch);
curl_setopt($curl, CURLOPT_URL, $item_url);
$data=curl_exec($curl);
file_put_contents($save_path . '/' . $filename , $data);
curl_close($curl);
}
return true;
}
//demon测试下载新浪首页全部图片
function microtime_float() {
list($usec, $sec) = explode(" ", microtime());
return ((float)$usec + (float)$sec);
}
$time_start = microtime_float();
graber_remote_image("http://www.sina.com.cn/", "/var/www/images/for");
$time_end = microtime_float();
$time = $time_end - $time_start;
echo "Time: $time seconds<br />";
curl_multi
<?php
error_reporting(E_ALL ^ E_NOTICE);
/**
* 远程图片并行下载
*
* 确保服务器配置有curl
*
* @param string $url
* @param string $save_path
* @return void
*/
function graber_remote_image($url, $save_path="./") {
set_time_limit(0);
ignore_user_abort(true);
if(!in_array('curl', get_loaded_extensions())){
die("curl not support !");
}
$ch = curl_init();
curl_setopt_array($ch, array(
CURLOPT_URL => $url,
CURLOPT_CONNECTTIMEOUT => 30,
CURLOPT_REFERER => !empty($_SERVER["HTTP_REFERER"]) ? $_SERVER["HTTP_REFERER"] : "",
CURLOPT_RETURNTRANSFER => 1,
CURLOPT_FOLLOWLOCATION => 1,
CURLOPT_USERAGENT => $_SERVER['HTTP_USER_AGENT']
));
$message = curl_exec($ch);
if(preg_match_all("/(http:\/\/|www\.)[^ \"']+/i", $message, $matches)){
$images_links = array();
foreach ($matches[0] as $item) {
$suffix = pathinfo($item, PATHINFO_EXTENSION);
if(in_array(strtolower($suffix), array('gif', 'png', 'jpg'))) {
array_push($images_links, $item);
//在这里进行简单修改可以选择性下载不同格式文件
}
}
}
if(empty($images_links)) {
die('get nothing image inforation.');
}
$images_links = array_unique($images_links);
@mkdir($save_path, 0777, true);
// Download images
$mh = curl_multi_init();
$handle = array();
foreach($images_links as $k=>$item_url){
$handle[$k]['thread'] = curl_copy_handle($ch);
$handle[$k]['filename'] = pathinfo($item_url, PATHINFO_BASENAME);
curl_setopt($handle[$k]['thread'], CURLOPT_URL, $item_url);
curl_multi_add_handle($mh, $handle[$k]['thread']);
//******************************************
// cpu load 100% problem *
//******************************************
// $running = null;
// do {
// curl_multi_exec($mh, $running);
// //usleep(1000000);
// } while ($running > 0);
//******************************************
// work well
//******************************************
do {
$status = curl_multi_exec($mh, $active);
$info = curl_multi_info_read($mh);
if (false !== $info) {
//var_dump($info);
}
} while ($status === CURLM_CALL_MULTI_PERFORM || $active);
}
foreach($handle as $item) {
$return = curl_multi_getcontent($item['thread']);
curl_multi_remove_handle($mh, $item['thread']);
file_put_contents($save_path . '/' . $item['filename'] , $return);
}
curl_multi_close($mh);
return true;
}
//demon测试下载新浪首页全部图片
function microtime_float() {
list($usec, $sec) = explode(" ", microtime());
return ((float)$usec + (float)$sec);
}
$time_start = microtime_float();
graber_remote_image("http://www.sina.com.cn/", "/var/www/images/multi");
$time_end = microtime_float();
$time = $time_end - $time_start;
echo "Time: $time seconds<br />";
结论
每个脚本跑50次,拉取所有图片,测试数据如下
- 图片个数:

- 图片大小

- 两种方式的耗时
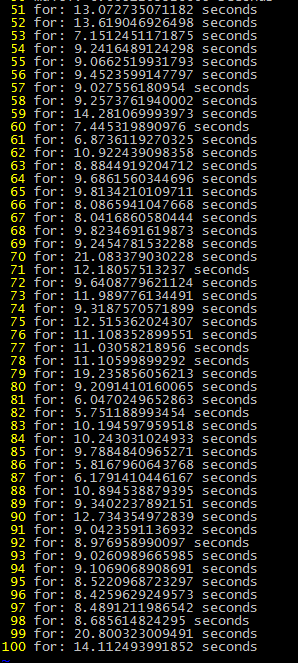
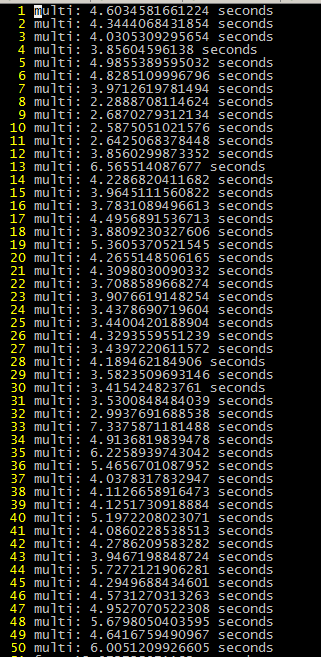
结论:从测试结果,很明显看的出,curl_multi多线程效率比for循环执行curl效率要高!